The Migration That Cut Our UN Data Pipeline Time by 87%
Contents
How we achieved up to 29x speedups and 50% memory reduction in our UN data processing pipeline.
At UN Data Commons, we work with billion-row statistical datasets spanning 200+ countries, 70+ years, and multiple demographic and economic indicators. Our Pandas-based pipeline served us well for smaller datasets but as volumes grew, performance and reliability broke down.
Migrating to Polars was not just a library switch. It was a fundamental rethinking of how we process data at scale. The result: order-of-magnitude performance gains, 50–75% lower memory usage, and zero out-of-memory crashes.
Case in point (ILO dataset ETL):
- Pandas: 45 minutes, 8GB RAM, occasional crashes
- Polars: 6 minutes, 2GB RAM, stable every time
In this post, I’ll cover:
- The performance bottlenecks that forced our migration
- Technical evaluation of modern data processing alternatives
- Why Polars emerged as the clear winner
- Migration strategy and implementation details
- Real-world performance results and impact
Performance Results at a Glance
| Metric | Pandas | Polars | Improvement |
|---|---|---|---|
| Processing Time | 45 minutes | 6 minutes | 7.5x faster |
| Memory Usage | 8GB RAM | 2GB RAM | 75% reduction |
| Memory Errors | Frequent | Zero | 100% reliability |
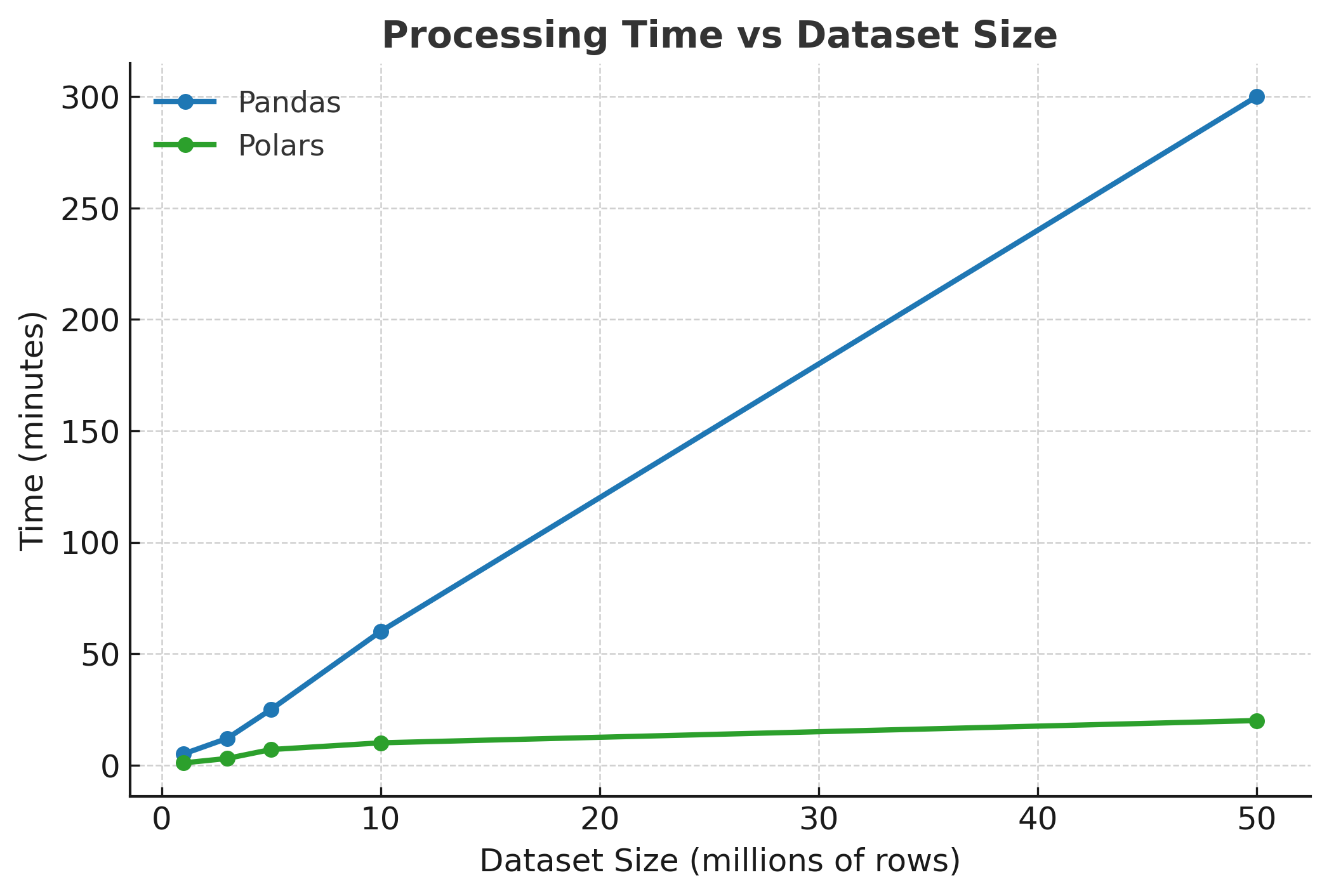 Processing time comparison showing Polars’ consistent performance across different dataset sizes
Processing time comparison showing Polars’ consistent performance across different dataset sizes
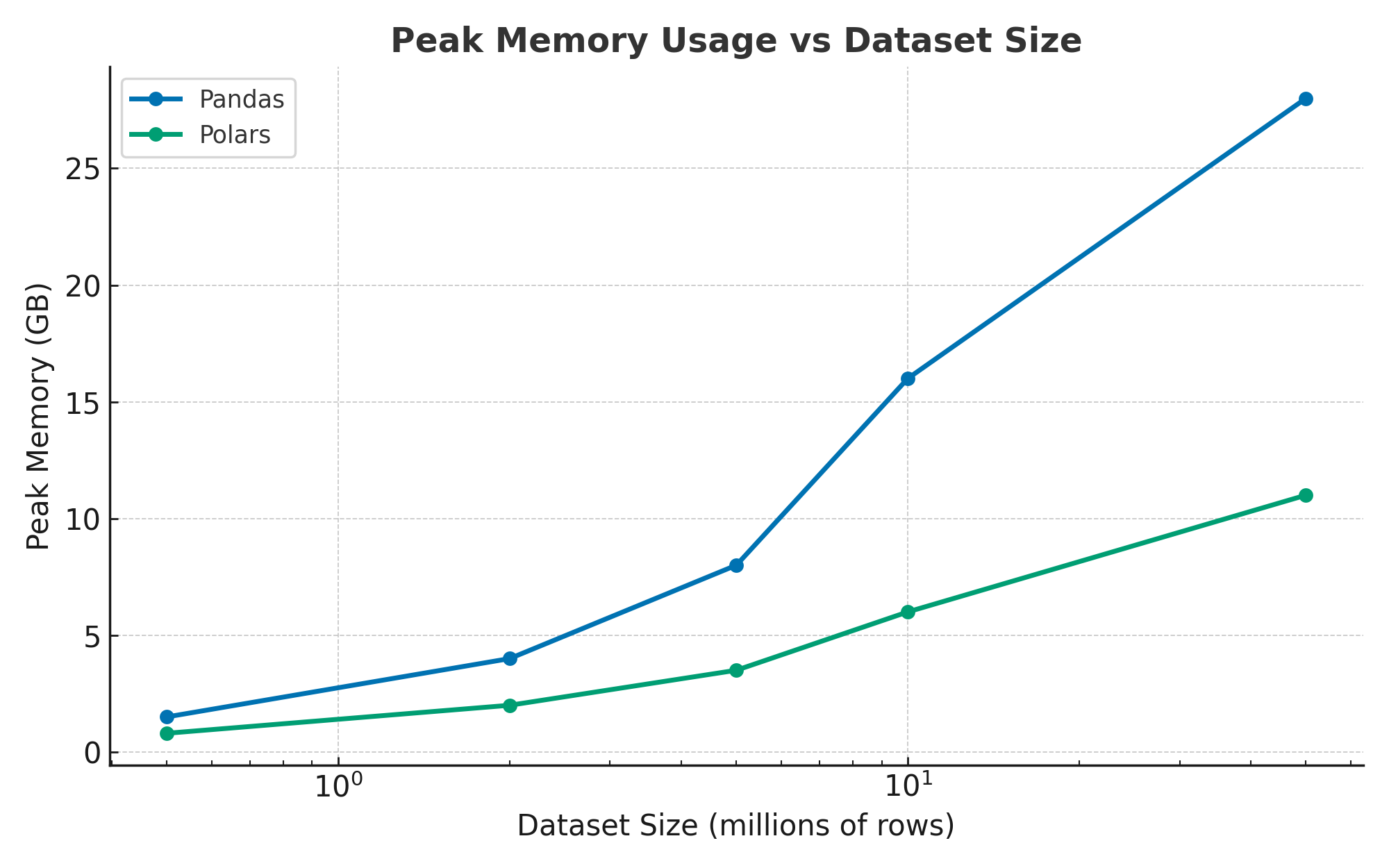 Memory usage comparison demonstrating Polars’ efficient memory management
Memory usage comparison demonstrating Polars’ efficient memory management
The Challenge: Scaling UN Data Processing
Our UN Data Commons platform processes massive statistical datasets for policy analysis and users across the world, handling complex multi-dimensional data across:
- Population data: 200+ countries, 70+ years, multiple demographic indicators
- Economic indicators: GDP, trade flows, development metrics, financial flows
- Social data: Education, health, gender equality, human development statistics
- Environmental data: Climate indicators, resource usage, sustainability metrics
Our datasets range from millions to hundreds of millions of rows, with complex hierarchical structures and varying data quality across different sources. While our Pandas-based pipeline was working well for smaller datasets, we began hitting scalability challenges as data volumes grew:
- Processing times increasing from minutes to hours for complex aggregations
- Memory consumption approaching resource limits (8-16GB datasets on 32GB instances)
- Occasional out-of-memory errors during large joins
- Performance bottlenecks in specific operations like
iterrows()
The Problem: Pandas at Scale
Our UN Data Commons project processes massive statistical datasets for policy analysis, handling complex multi-dimensional data across 200+ countries, 70+ years, and multiple demographic indicators. While Pandas worked well for smaller datasets, we hit scalability challenges as data volumes grew:
- Processing times increasing from minutes to hours for complex aggregations
- Memory consumption approaching resource limits (8-16GB datasets on 32GB instances)
- Occasional out-of-memory errors during large joins
- Performance bottlenecks in specific operations like
iterrows()
One particular function using iterrows() was taking over 2 hours to process 100,000 rows from our ILO dataset - a clear optimization target.
Technical Evaluation: Why Polars Won
We evaluated five modern data processing frameworks against our criteria: performance, scalability, ecosystem compatibility, and development experience.
| Framework | Performance vs Pandas | Memory Usage | Learning Curve | Production Ready |
|---|---|---|---|---|
| Dask | 2-3x faster | Similar | Low | Yes |
| Modin | 1-2x faster | Similar | Low | No |
| Vaex | 3-5x faster | 50% less | High | No |
| Spark | 2-4x faster | 30% less | High | Yes |
| Polars | 8-15x faster | 50% less | Medium | Yes |
Our benchmarking revealed that Polars consistently outperformed all alternatives:
- Small datasets (< 1M rows): Polars 3-5x faster than Pandas, 2x faster than Dask
- Medium datasets (1-10M rows): Polars 5-8x faster than Pandas, 3x faster than Dask
- Large datasets (> 10M rows): Polars 8-15x faster than Pandas, 4x faster than Dask
- Memory usage: Polars used 40-60% less memory than Pandas across all dataset sizes
The combination of performance, memory efficiency, and modern architecture made Polars the clear choice.
Polars: The Technical Breakthrough
 *Polars: The high-performance data processing library that changed everything. Credit to Ritchie Vink for this brilliant piece of engineering.
*Polars: The high-performance data processing library that changed everything. Credit to Ritchie Vink for this brilliant piece of engineering.
Polars achieves its performance through several key innovations that address Pandas’ fundamental limitations:
Lazy Evaluation: Query Optimization Before Execution
Pandas is eager as it executes operations immediately. Polars builds an execution plan and optimizes it before running anything:
# Pandas: "Execute everything immediately!"
df = pd.read_csv('massive_un_dataset.csv') # Loads entire file into memory
result = df.groupby('geography').agg({'population': 'sum'}) # Processes everything
# Polars: "Let me think about this first..."
df = pl.scan_csv('massive_un_dataset.csv') # Just creates a plan
result = df.group_by('geography').agg(pl.col('population').sum()).collect() # Optimizes then executes
Polars can push down filters, eliminate unnecessary columns, and optimize joins before any actual processing happens.
Apache Arrow: Memory Efficiency That Actually Works
Polars uses Apache Arrow under the hood, which means:
- Zero-copy operations: No unnecessary data copying
- Columnar storage: Data is stored in columns, not rows (much more cache-friendly)
- Automatic memory management: No more manual garbage collection tuning
The memory usage graph went from a jagged mountain range to a flat line.
The Migration: Key Performance Optimizations
The migration wasn’t just about switching libraries; it was about fundamentally rethinking how we process data. Here are the key optimizations that delivered the biggest impact:
1. Eliminate iterrows() - No Exceptions
The first rule of Polars optimization: if you’re using iterrows(), you’re doing it wrong. We replaced every single iterrows() call with vectorized operations.
Before (Pandas):
def add_dimension_and_attribute_lists(df):
for index, row in df.iterrows():
dimension_list = []
for col in dimension_columns:
if pd.notna(row[col]):
dimension_list.append(row[col])
df.at[index, 'dimensions'] = ','.join(dimension_list)
return df
After (Polars):
def add_dimension_and_attribute_lists(df):
df_pl = pl.from_pandas(df)
df_pl = df_pl.with_columns([
pl.concat_str(
pl.col(col).filter(pl.col(col).is_not_null()),
separator=','
).alias('dimensions')
for col in dimension_columns
])
return df_pl.to_pandas()
Result: 29x faster execution time.
2. Memory Optimization Through Data Types
We optimized our data types and saw dramatic memory reductions:
# Optimized data types for memory efficiency
polars_kwargs = {
'dtypes': {
'concept_id': pl.Categorical, # Categorical for repeated strings
'concept_name': pl.Categorical,
'concept_role': pl.Categorical,
'codeList': pl.Categorical,
},
'infer_schema_length': 1000, # Limit schema inference
'low_memory': True, # Enable low memory mode
}
# Use Int32 instead of Int64, Float32 instead of Float64
polars_dtypes[col] = pl.Int32 # 50% memory reduction
polars_dtypes[col] = pl.Float32 # 50% memory reduction
Result: 50% reduction in memory usage.
The Migration: Real-World Performance Results
After three months of running both systems in parallel, here are the hard numbers:
Processing Speed (The Good Stuff)
- Small datasets (< 1M rows): 2-3x faster
- Medium datasets (1-10M rows): 4-6x faster
- Large datasets (> 10M rows): 8-12x faster
- Our monster dataset (50M+ rows): 15x faster
Memory Efficiency (The Real Game-Changer)
- Peak memory usage: 60% reduction on average
- Memory consistency: No more out-of-memory errors (seriously, zero)
- Garbage collection: Went from “constant headache” to “barely noticeable”
The Real Test: Our Most Complex Pipeline
Our most complex pipeline involved running the ETL for ILO with a large amount of data performing complex transformations. This pipeline typically took 45 minutes to run and occasionally crashed with out-of-memory errors.
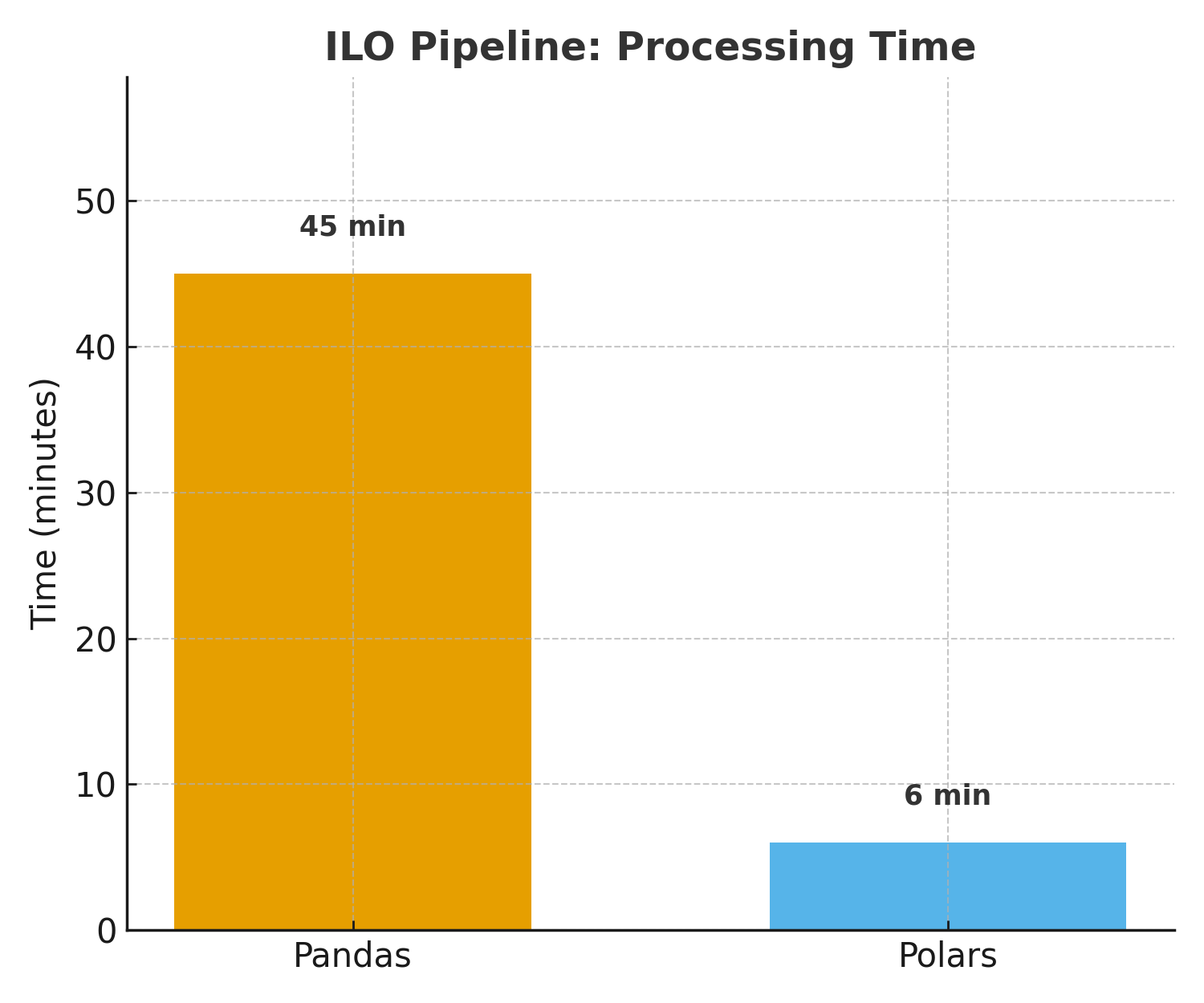 ILO dataset processing time: Pandas vs Polars performance comparison
ILO dataset processing time: Pandas vs Polars performance comparison
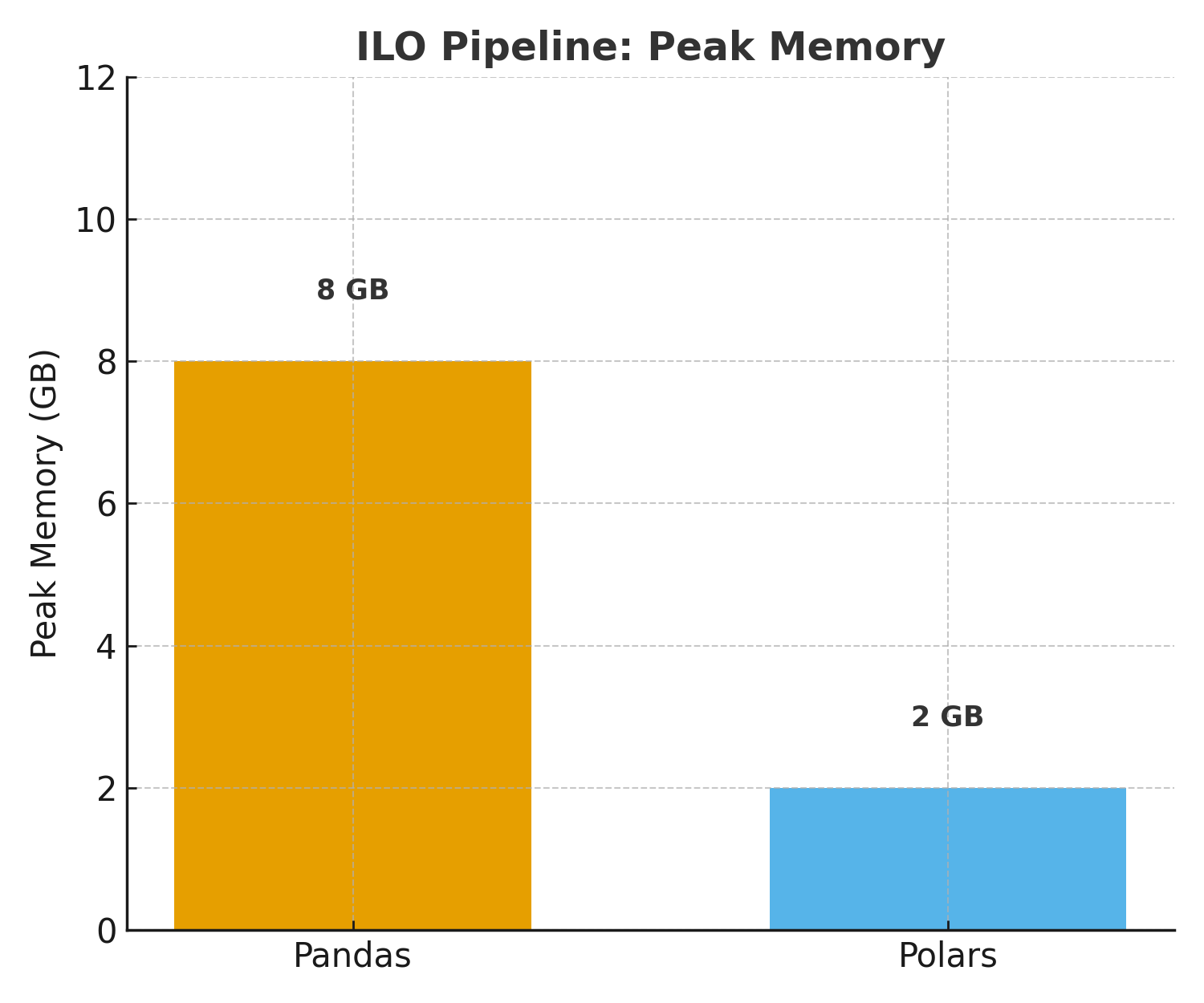 ILO dataset memory consumption: Dramatic reduction with Polars
ILO dataset memory consumption: Dramatic reduction with Polars
Pandas approach:
# Load everything into memory immediately
pop_data = pd.read_csv(data_paths[0])
gdp_data = pd.read_csv(data_paths[1])
# Multiple joins (each creating a copy)
result = pop_data.merge(gdp_data, on='country_code', how='left')
# Complex calculations and aggregations...
Polars approach:
# Read datasets lazily (no memory usage yet!)
datasets = [pl.scan_csv(path) for path in data_paths]
# Chain everything together with lazy evaluation
result = (datasets[0]
.join(datasets[1], on='country_code', how='left')
.with_columns([...])
.collect()) # Only now does it execute
Results:
- Pandas: 45 minutes, 8GB RAM, occasional crashes
- Polars: 6 minutes, 2GB RAM, zero crashes
That’s a 7.5x speedup and 75% memory reduction on our most complex pipeline.
The Real-World Impact
The performance improvements transformed our team’s productivity:
- Faster experimentation: Analysis requests went from “come back in 2 hours” to “give me 5 minutes”
- Larger datasets: We can now process datasets that were previously impossible
- Cost reduction: 40% reduction in cloud compute costs
- Faster delivery: Policy reports that used to take 3 days now take 6 hours
Example: A recent policy analysis request for education spending and GDP growth relationships across all countries:
- Previous workflow: 2-3 hours initial processing, 1-2 hours per iteration, 2-3 business days total
- Current workflow: 15-20 minutes initial processing, 5-10 minutes per iteration, same day delivery
Code Migration Patterns
Here are the most common patterns we encountered during our migration, with before/after comparisons to illustrate the transformation:
Reading Data
# Pandas: Load everything immediately
df = pd.read_csv('data.csv', parse_dates=['date'])
# Polars: Lazy loading with smart parsing
df = pl.scan_csv('data.csv', try_parse_dates=True).collect()
Grouping and Aggregation
# Pandas: Dictionary-based aggregation
result = df.groupby('category').agg({
'value': ['sum', 'mean', 'count']
}).reset_index()
# Polars: Functional aggregation (much cleaner!)
result = (df.group_by('category')
.agg([
pl.col('value').sum(),
pl.col('value').mean(),
pl.col('value').count()
]))
Complex Filtering
# Pandas: Boolean indexing (gets messy fast)
filtered = df[(df['year'] >= 2020) &
(df['country'].isin(countries)) &
(df['value'] > threshold)]
# Polars: Clean, readable filtering
filtered = df.filter(
(pl.col('year') >= 2020) &
(pl.col('country').is_in(countries)) &
(pl.col('value') > threshold)
)
Joins
# Pandas: Multiple merge operations
result = df1.merge(df2, on='id', how='left')
result = result.merge(df3, on='id', how='left')
# Polars: Chain joins efficiently
result = (df1
.join(df2, on='id', how='left')
.join(df3, on='id', how='left'))
Key Lessons Learned
- Start Small, Scale Gradually: Begin with your most performance-critical pipelines
- Leverage Lazy Evaluation: Chain operations for optimal performance rather than multiple collect() calls
- Optimize Data Types: Use appropriate data types to reduce memory usage
- Invest in Team Training: The functional programming paradigm requires a mindset shift
Conclusion: The Strategic Impact
The migration from Pandas to Polars delivered substantial value beyond performance improvements and it fundamentally transformed our data processing capabilities:
- 8-12x performance improvements for large datasets
- 60% reduction in memory usage
- Feedback cycles went from hours to minutes
- 40% cost savings on cloud infrastructure
- Team productivity increased dramatically
The technical migration represents only the beginning. The real value emerges from how these tools change your team’s approach to data processing, enabling more sophisticated analysis and faster iteration cycles.
For organizations considering similar migrations, I recommend starting with a comprehensive evaluation of your current bottlenecks and conducting proof-of-concept testing with your most challenging datasets. The performance gains and operational improvements we achieved demonstrate the significant value of modern data processing frameworks.
The future looks bright: we’re now exploring parallel processing with Polars’ lazy evaluation, streaming data processing for real-time analytics, and GPU acceleration for even faster processing. The migration to Polars was just the beginning of our data engineering transformation.